Les bases pour modéliser une base de données
Publié leQuelle méthode pour conceptualiser une base de données à partir d'une simple expression de besoins ?
DISCLAIMER : Cet article aborde une approche de modélisation issue de la méthode de Merise. Il existe de nombreuses autres méthodes et approches qui font varier la complexité.
Préfigurer un modèle de données
Prenons l’exemple d’une sollicitation d’un service marketing qui procède à des enquêtes de satisfaction client. Celui-ci souhaite sortir de son modèle traditionnel de récolte de questionnaire de satisfaction papier puis traitement sous tableur. Le service exprime le besoin de centraliser les réponses obtenues et d’automatiser l’envoi d’enquêtes par mail.
Suite à une réunion de cadrage et qualification du besoin, vous repartez avec cette problématique affinée : “des chefs de projets marketing sont en charge de l’élaboration d’enquêtes clients. On souhaite à terme spécialiser chaque chef de projet marketing sur une typologie d’enquête, chaque type d’enquête à des questions specifiques mais toutes les enquêtes commencent par un bloc de questions communes. Il faut que l’on puisse tracer quelle enquête a été crée par quel chef de projet marketing. Tous les types d’enquête recueillent l’âge, le nom, l’adresse du client. Nous souhaitons que les enquêtes soient adressées par mail aux clients.”
Avant d’entrer dans la conception de la solution numérique, il est nécessaire de conceptualiser notre modèle de données. En effet, celui-ci conditionnera l’architecture de la solution. Il prendra la forme d’un schéma qui matérialisera les différentes relations entre nos données. Pour cela, voyons plus en détail une méthode simple à utiliser.
Dictionnaire de données
La méthode Merise invite à mener des interviews et à analyser les documents utilisés par le service dans le but d’établir le dictionnaire de données. Il s’agit d’un tableau qui recense toutes les données que comporte le problème. Une donnée est une occurence non-décomposable qui est amenée à varier. Le tableau précise les caractéristiques de la donnée retenue.
| Nom de la donnée | Format | Taille | Type élémentaire ou calculé | Document associé |
|---|---|---|---|---|
| age_client | Entier | 3 | Elémentaire | Fiche client |
| nom_client | Alphabétique | 40 | Elémentaire | Fiche client |
| prenom_client | Alphabétique | 40 | Elémentaire | Fiche client |
| numero_de_rue_client | Alphanumérique | 5 | Elémentaire | Fiche client |
| nom_de_rue_client | Alphabétique | 40 | Elémentaire | Fiche client |
| cp_client | Entier | 5 | Entier | Fiche client |
| ville_client | Alphabétique | 40 | Elémentaire | Fiche client |
| nom_categorie | Alphabétique | 20 | Elémentaire | Enquete |
| questions_specifiques_categorie | Alphanumérique | 100 | Elémentaire | Enquete |
| questions_communes_enquete | Alphanumérique | 100 | Elémentaire | Enquete |
| nom_chef_projet_marketing | Alphabétique | 40 | Elémentaire | / |
| prenom_chef_projet_marketing | Alphabétique | 40 | Elémentaire | / |
Le bloc “Adresse” a été divisé en 4 données séparées : “n° de rue”, “nom de rue”, “CP” et “Ville”. En effet “Adresse” était décomposable, or si l’on souhaite à terme requêter le nombre de clients qui ont participés à l’enquête dans une ville précise il est nécessaire d’avoir un champ séparé pour la ville.
Les dépendances fonctionnelles
A la suite du dictionnaire de données, il peut être utile d’identifier quelles données dépendent de quel identifiant unique.
| Identifiant unique | Données dépendantes fonctionnellement |
|---|---|
| id_client | age_client, nom_client, prenom_client, numero_rue_client, nom_rue_client, cp_client, ville_client |
| nom_categorie | questions_specifiques_categorie |
| chef_marketing_id | nom_chef_projet_marketing, prenom_chef_projet_marketing |
| id_enquete | questions_communes_enquete |
Le Modèle Conceptuel de Données
Plusieurs types de schémas conceptuels existent, correspondants aux différents types de base de données que l’on peut rencontrer :
- le modèle hiérarchique
- le modèle réseaux sémantiques
- le modèle entité / attribut / relation (appelé ERD en anglais)
- le modèle objet
Par souci de simplicité nous nous appuierons sur le modèle entité / attribut / relation qui est fréquemment utilisé pour les bases de données relationnelles.
Si vous ne savez pas ce qu’est une base de données relationnelle ou dans quels cas l’utiliser, je vous invite à consulter mon article sur le sujet.
Le fondement de notre BDD repose sur les entités : elles représentent les sujets qui composent le processus informationnel pour lequel nos données seront enregistrées. Une entité possède des attributs : il s’agit de propriétés qui caractérisent l’entité. Par exemple pour une entité “citoyen” les attributs pourront être “âge, genre, situation familiale”.
Pour passer du dictionnaire de données à la modélisation des Entités-Attributs, on regroupe les données qui ont un lien entre elles en se demandant de quelles données uniques elles dépendent. Voici la modélisation de notre problème posé en introduction :
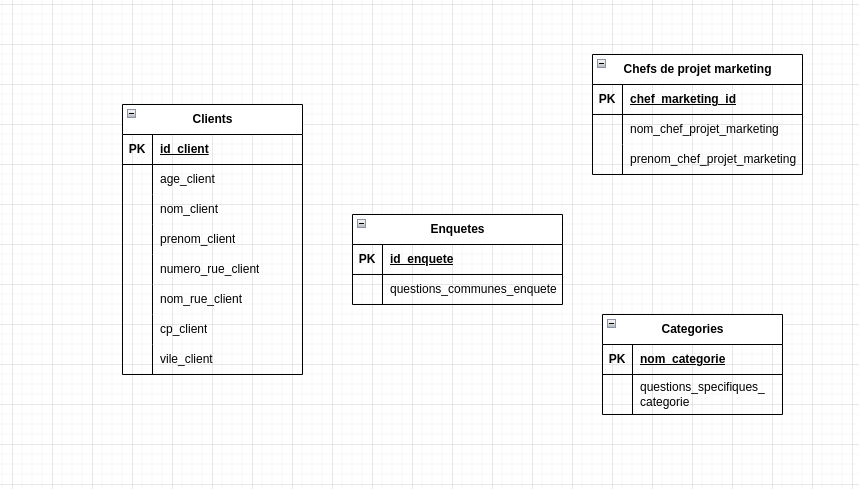
Les relations et leurs cardinalités
Les relations décrivent comment les entités interagissent entre elles. Les relations sont généralement marquées par des verbes “achète à”, “est traité par”… La relation peut comporter des attributs, on l’appelle alors “relation porteuse”.
Les cardinalités sont des indicateurs qui matérialisent la qualité de la relation entre deux entités. Par exemple pour deux entités “Enquêtes” et “Clients”, les cardinalités sont le nombre de clients pour lesquelles il peut exister a minima et a maxima une ebquête et inversement.
La méthode pour les définir est de toujours exprimer un minimum : “Un client peut remplir au minimum combien d’enquêtes ? 0, 1 ou n ? (n représentant l’infini)”. Et un maximum :“Un client peut remplir au maximum combien d’enquêtes ? 0, 1 ou n ?”.
Ces cardinalités sont précieuses car elles nous permettront de vérifier la qualité de notre modèle puis de transformer le modèle en tables grâce à des règles de normalisation.
Voici, pour notre exemple, les relations et leurs cardinalités :
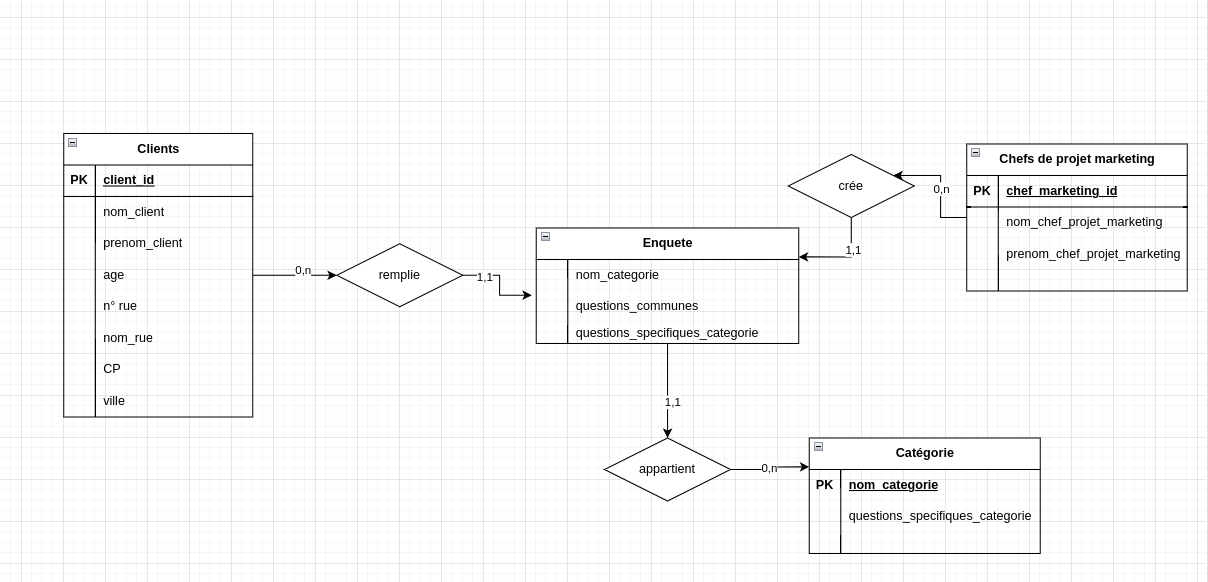
Cas particulier de la nécessité de concaténer plusieurs identifiants pour identifier de manière unique
Prenons un tout autre exemple avec un modèle conceptuel de données qui stockerait des informations au sujet d’appartements, l’étage, l’immeuble et la rue auxquels ils se rattachent. Un appartement ne peut pas être identifié de manière unique par sa lettre_appartement car il peut y avoir un appart A au 1er étage et un appart A au 2ème étage, on exprime alors avec les parenthèses autour des cardinalités que les entités du côté de ces cardinalités seront identifiées par la concaténation des identifiants de toute la chaîne de la relation.
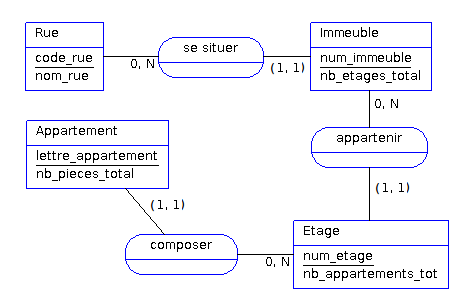
Rue (code_rue, nom_rue)
Immeuble (num_immeuble, code_rue#, nb_etages_total)
Etage (num_etage, num_immeuble#, code_rue#, nb_appartements_tot)
Appartement (lettre_appartement, num_etage#, num_immeuble#, code_rue#, nb_pieces_total)Clé primaire et étrangère
Le principe de clés est indispensable pour faire référence à un enregistrement précis d’une table. La clé primaire est l’identifiant unique d’une entité. Celle-ci peut-être artificielle, c’est à dire créée de toute pièce, ou être naturellement candidate c’est à dire être une colonne déjà existante ou la concaténation de plusieurs colonnes. La clé étrangère est une référence à l’identifiant unique d’une autre entité. Utile pour mettre en relation deux enregistrements qui ont un rapport entre eux.
Comment schématiser facilement notre Modèle Conceptuel de Données
J’utilise l’outil gratuit en ligne Draw.io qui a un sous-menu dédié “Relation entre les éléments”.
Sources
https://fr.wikiversity.org/wiki/Introduction_aux_systèmes_de_bases_de_données/Introduction/