Produire un document print sans logiciels propriétaires grâce aux technologies du web
Publié le Mis à jour leComment produire un document texte et le mettre en forme sans utiliser d'outils propriétaires ?
Doctrine : pourquoi sortir des logiciels de traitement de texte
Microsoft Word, LibreOffice, Google Docs, ces logiciels de création et modification de documents sont les premiers qui viennent à l’esprit quand on doit produire du texte. Pourtant ceux-ci apportent leur lot de difficulté en conditionnant la production du texte à travers les choix implicites de l’éditeur du logiciel. Ceux-ci ne sont pas neutres.
En sciences humaines et sociales, les logiciels de traitement de texte, comme LibreOffice Writer, Microsoft Word et Google Docs, sont utilisés par la majorité des auteurs et des éditeurs. Ce sont des outils polyvalents, puissants, capables de gérer toutes les étapes de la chaîne éditoriale. Mais leurs avantages sont contrebalancés par une série d’inconvénients plus ou moins problématiques. D’abord, et du fait de leur polyvalence, ces logiciels tendent souvent vers l’usine à gaz. Leur interface est notoirement encombrée, pleine de distractions. Et ils sont gourmands en ressources (énergie, mémoire) ; or malgré cela, ils gèrent mal les documents longs et complexes. Ensuite, ce sont des logiciels ancrés dans le paradigme de l’imprimé, qui sont donc fondamentalement inadaptés à la communication via le Web. Dans un monde où le papier et le numérique sont appelés à cohabiter durablement, c’est une lacune considérable. Autre problème : leur modèle économique (en tout cas pour les logiciels propriétaires) est de moins en moins avantageux pour le consommateur. La tendance est à l’abonnement : payer pour accéder à ses propres données, sans aucune garantie sur la longévité du service. Enfin, leurs formats sont soit complètement fermés (.doc), soit difficiles à utiliser via d’autres outils (.docx). Les logiciels de traitement de texte verrouillent les auteurs dans un écosystème propriétaire dans lesquels les choix sont réduits. Certes, LibreOffice existe; mais la compatibilité entre formats a des limites, situation entretenue par les éditeurs de logiciels commerciaux car ils en tirent profit.
PERRET, Arthur. Cours sur l’écriture scientifique au format texte. 2022
Au-delà des des difficultés directes qu’entraînent les logiciels de traitement de texte, explorons leur effet sur la “chaîne de publication”. Antoine Fauchié a consacré sa thèse de doctorat à la question “Vers un système modulaire de publication : éditer avec le numérique”.
Antoine Fauchié décrit les étapes de fabrication d’un document : Écrire → Partager, valider → Composer → Générer, publier
- “Ecrire” : les logiciels de traitement de texte apposent automatiquement un style à l’écriture alors qu’au début du processus d’écriture on souhaite plutôt se concentrer uniquement sur le sens de l’écrit et sur la structure sémantique.
- “Partager, valider” : la gestion de l’édition à plusieurs. Les allers-retours de version du document par mail entre les différents contributeurs n’est pas idéale. On a plutôt besoin de versionner le document pour éviter les allers-retours entre les différents contributeurs. La méthode “Word” est d’utiliser le nom du document pour versionner “presentation-inha-v3-corrections-antoine-ok-jeudi.doc”. Au bout de multiples allers-retours la technique de versionnage par le nom du document montre ses limites. Se pose aussi la question de la collaboration à plusieurs sur le même document : procède-t-on par échange de mails ? par commentaire ? Et comment conserver l’historique des modifications pour revenir à une version d’il y a 6 mois ?
- “Composer” : mise en forme du document. Pour une mise en forme classique certains utiliseront les styles de Word, pour une mise en forme avancée des designers utiliseront Adobe InDesign. Dans les deux cas, la mise en forme du document par un logiciel propriétaire entraîne une certaine rupture dans la collaboration : un non-initié à InDesign pourra difficilement apporter des modifications à la mise en forme. On se confronte également rapidement aux modèles économiques changeant d’Adobe et comparses
- “Générer, publier” : on rencontre un écueil majeur : les documents produits par un logiciel de traitement de texte ignore les formats “modernes” d’affichage du texte. Quid de l’affichage du texte dans une page web ? Quid de l’affichage responsive du texte sur un mobile ? Quid de l’accessibilité d’un PDF pour les personnes en situation de handicap visuel ?
Alors, quelles solutions ?
Julie Blanc a représenté le fonctionnement d’une chaîne éditoriale reposant sur une source unique et s’appuyant sur les technologies du web.
Julie Blanc est docteure en ergonomie et design de l’Université Paris 8. Sa thèse porte sur l’utilisation des technologies du web pour l’impression par les designers graphiques. Elle explique avec justesse les dangers de s’appuyer uniquement sur des logiciels propriétaires dans le travail de mise en forme graphique.
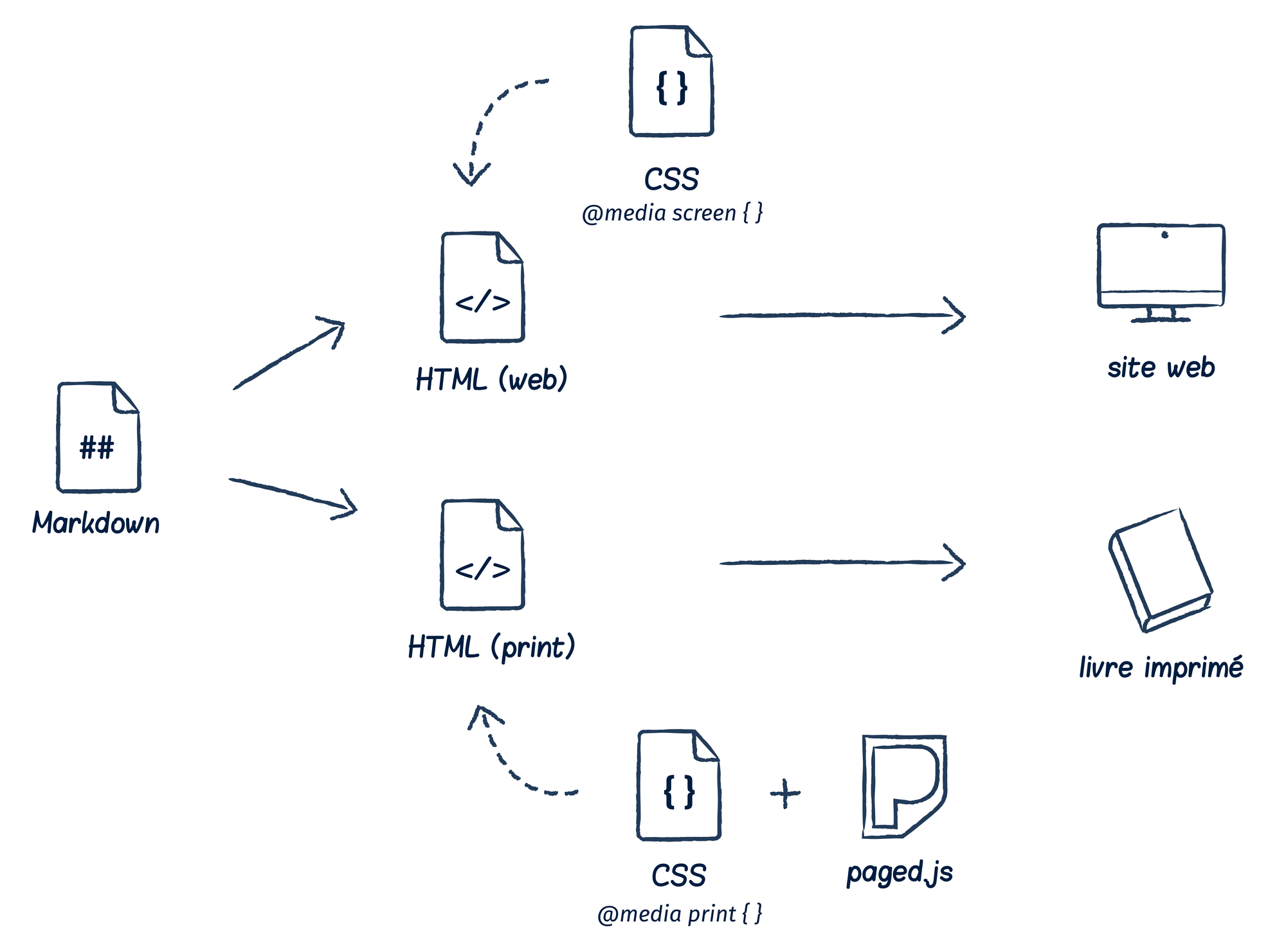
On peut reprendre les étapes de fabrication d’un document recommandé par Antoine Fauchié : Écrire → Partager, valider → Composer → Générer, publier. Ci-dessous une proposition d’outillage pour faciliter le processus. Celle-ci dépend bien sûr des usages de chacun et repose sur le principe d’une source unique (l’idée du Single Source Publishing est de pouvoir produire des formes différentes à partir d’une même source). D’autres chaînes de publication peuvent-être plus adaptées selon les contextes.
-
Pour l’étape “Ecrire”, on s’appuie sur le format
Markdown. Il s’agit d’un langage de balisage léger permettant de se concentrer d’abord sur le fond du texte plutôt que sur la forme. le processus d’écriture est plus fluide qu’enHTML. La syntaxe est simple à apprendre.« Markdown » c’est deux choses : une syntaxe de balisage de texte brut et un outil logiciel qui convertit le balisage de texte brut en HTML pour la publication sur le web.
BRASSARD, Louis-Olivier. Extrait du cours de Debugue tes humanités sur les langages de balisage. 2018Plutôt que de rédiger du texte non structuré, ou à l’inverse de devoir connaître une trop importante somme de balises HTML, Markdown traduit simplement une intention sémantique via une syntaxe simple compréhensible par des humains.
FAUCHIE, Antoine. Extrait d'un billet de blog à propos du format Markdown. 2018 -
L’étape “Partager, valider” supporte tout le processus d’édition : on souhaite suivre les modifications proposées par les différents contributeurs et versionner le document facilement. Git est un protocole libre de versionnage et suivi des modifications. Celui-ci simplifie grandement la collaboration en permettant à tous les contributeurs de proposer des modifications qui peuvent être soumises pour approbation. Il permet également de retracer toutes les modifications et de restaurer des versions très antérieures. Git présente de formidables opportunités pour faciliter la collaboration dans le monde professionnel : il évite de nombreux allers-retours de document et permet de sortir de l’approche “modification des documents dans la colonne de commentaire Word”. On peut l’utiliser pour versionner la mise en forme si l’on travaille via des langages de mise en forme (CSS). Git ne peut cependant pas traiter de fichiers binaires, exit donc les formats “doc, docx, odt…” mais il gère tous les fichiers en lignes numérotées donc Markdown, HTML, CSS…
Git, ce n’est pas un outil, c’est plutôt un protocole de travail. Git, c’est une façon de travailler, de gérer des documents dans l’espace et dans le temps. [...] Git répond au problème : "je travaille sur un projet avec plusieurs fichiers informatiques (n’importe lesquels) et je cherche à éviter d’avoir des titres à rallonge comme fichier_reluparXX_v1, v2, etc." L’idéal, si c’est utilisé au sein d’une équipe, c’est de le mettre en place dès que les fichiers arrivent et que le travail commence. Ça évite les problèmes de nomenclature dont on parlait, et le risque de ne pas tous.tes travailler sur la bonne version. Git va venir structurer la façon de travailler, ça va la contraindre aussi, forcément. Ce n’est pas une méthode totalement ouverte, elle va avoir des impacts sur la façon de travailler.Ce qui est intéressant, c’est que tu vas pouvoir tracer toutes les modifications en fonction des rôles des personnes qui composent l’équipe; tout le monde peut travailler de façon parallèle, plusieurs personnes peuvent travailler sur le même fichier en même temps et ensuite fusionner les différentes contributions. Chacun.e travaille sur un fichier sur son ordinateur et versionne son travail, sans forcément être connecté.e à Internet. Une connexion est seulement nécessaire pour envoyer les modifications sur un dépôt commun. Il peut y avoir des conflits, s’il y a eu des modifications aux mêmes endroits.
FAUCHIE, Antoine. Extrait d'une interview à propos du protocole Git comme outil d'édition et d'écriture. 2022 -
L’étape “Composer” consiste en la conversion du fichier Markdown vers du HTML. On met en forme via des feuilles de style CSS qui permettent d’aller bien plus loin dans la personnalisation que ce qu’offrent la plupart des logiciels de mise en forme graphique.
-
L’étape “Générer, publier” consiste en l’adaptation du HTML et du CSS aux formats souhaités : print, mobile, desktop… PagedJS est une librairie Javascript open source gratuite qui pagine le contenu comme ce qui peut-être attendu dans un format livre. PagedJS a été initié par Adam Hyde et est développé par Julie Blanc, Fred Chasen et Julien Taquet.
Une introduction pratique à la conception de documents sans logiciel de traitement de texte
Etape 1 : conversion du Markdown vers HTML grâce à Pandoc
Pandoc est l’outil en ligne de commande à installer pour convertir du Markdown vers du HTML : pandoc [NCA.md](http://nca.md/) -o NCA.html --standalone --extract-media=media
- l’attribut
—standaloneest important car il indique à Pandoc de créer un document HTML ENTIER autour de notre HTML et non pas d’exporter juste un body HTML —extract-media=mediapermet de spécifier le nom du dossier où seront stockées les images
On se retrouve avec un fichier HTML sans style.
Etape 2 : mise en forme minimale via PagedJS
Pour que PagedJS agisse sur notre document HTML il est nécessaire de placer le polyfill en tant que script dans notre document HTML. Le fichier polyfill se récupère dans la documentation
Il faut l’appeler dans le <head> : <script src="paged.polyfill.js"></script>
Dernière étape avant de pouvoir apercevoir le rendu de notre document dans le navigateur : il faut récupérer un fichier CSS constituant “l’interface d’affichage du document” c’est à dire un découpage du document en plusieurs pages visuelles plutôt que la visualisation par défaut d’un document HTML.
Le fichier interface.css est à récupérer ici. On place le fichier dans le <head> : <link rel="stylesheet" href="interface.css" type="text/css" />

Jusqu’ici nous n’avons pas touché au style de notre document, nous nous sommes contentés de mettre en place l’affichage en “page séparées” et la technologie de mise en page print.
On peut désormais ajouter une feuille de style à notre fichier HTML dans le <head> : <link rel="stylesheet" href="tufte.css" type="text/css" />.
On commence par définir les gabarits de page :
@charset "UTF-8";
@page {
size: A4;
margin: 28mm 22mm 21mm 27mm; /*Tufte typical margins*/
}Tout l’intérêt de l’outil réside dans sa flexibilité : on peut définir n’importe quel gabarit de page et n’importe quel type de marge grâce à @page : une règle CSS spécifique à l’impression de documents. Ici j’applique des marges spécifiques, non-standards, pour appliquer le style “Tufte”.
Enfin, PagedJS ne bénéfice pas du Hot Module Replacement (HMR) offert par les outils de build type Vite et frameworks web : ceux-ci permettent de voir les changements effectués dans le code source en temps réel sans rechargement de la page.
Dans PagedJS on est obligé de réactualiser manuellement la page si l’on a pas activé une surveillance spécifique de certains fichiers et la page remonte tout en haut. Pas pratique quand on est entrain de modifier la 28ème page par exemple !
Nicolas Taffin a créé le script reload-in-place.js pour que la page scroll automatiquement sur le dernier endroit que vous étiez entrain de modifier avant le reload de la page.
Etape 3 : étendre les fonctionnalités de base offertes par PagedJS
Assez rapidement, on se rend compte qu’il manque trois éléments élémentaires dans la mise en page print :
- Une numérotation des pages (automatique)
- Un sommaire (généré automatiquement)
- Un moyen de faire commencer certains titres automatiquement sur une nouvelle page (on ne souhaite pas avoir un titre de niveau 2 qui commence à la dernière ligne d’une page)
Une partie des plugins d’extenstion de PagedJS se trouve sur le repo https://gitlab.coko.foundation/pagedjs/pagedjs-plugins
Comment numéroter les pages ?
Il suffit d’ajouter dans un de nos fichier CSS :
/* Numérotation des pages */
@page :left {
@bottom-right {
content: counter(page);
}
}
@page :right {
@bottom-right {
content: counter(page);
}
}
/* pas de numéro de page pour la couverture : requiert de wrapper d'une <div data-page=macouverture></div> le contenu de notre page dans notre HTML*/
@page macouverture {
@bottom-right {
content: none;
}
@bottom-left {
content: none;
}
}Les pages de gauche recoivent leur numéro de page, incrémenté automatiquement, en bas à droite dans la marge.
Les pages de droite de même.
La page de couverture n’est pas numérotée.

Comment mettre en place un sommaire automatique ?
Le script de génération automatique d’un sommaire via PagedJS a été conçu par l’Atelier ESAD Pyrénées - Julien Bidoret.
Il consiste en un fichier createToc.js :
function createToc(config){
const content = config.content;
const tocElement = config.tocElement;
const titleElements = config.titleElements;
let tocElementDiv = content.querySelector(tocElement);
let tocUl = document.createElement("ul");
tocUl.id = "list-toc-generated";
tocElementDiv.appendChild(tocUl);
// add class to all title elements
let tocElementNbr = 0;
for(var i= 0; i < titleElements.length; i++){
let titleHierarchy = i + 1;
let titleElement = content.querySelectorAll(titleElements[i]);
titleElement.forEach(function(element) {
// add classes to the element
element.classList.add("title-element");
element.setAttribute("data-title-level", titleHierarchy);
// add id if doesn't exist
tocElementNbr++;
idElement = element.id;
if(idElement == ''){
element.id = 'title-element-' + tocElementNbr;
}
let newIdElement = element.id;
});
}
// create toc list
let tocElements = content.querySelectorAll(".title-element");
for(var i= 0; i < tocElements.length; i++){
let tocElement = tocElements[i];
let tocNewLi = document.createElement("li");
// Add class for the hierarcy of toc
tocNewLi.classList.add("toc-element");
tocNewLi.classList.add("toc-element-level-" + tocElement.dataset.titleLevel);
// Keep class of title elements
let classTocElement = tocElement.classList;
for(var n= 0; n < classTocElement.length; n++){
if(classTocElement[n] != "title-element"){
tocNewLi.classList.add(classTocElement[n]);
}
}
// Create the element
tocNewLi.innerHTML = '<a href="#' + tocElement.id + '">' + tocElement.innerHTML + '</a>';
tocUl.appendChild(tocNewLi);
}
}
on appelle le fichier createToc.js dans le <head> accompagné d’un script secondaire directement intégré dans notre document HTML :
<!--createToc génère la table des matières à condition de placer <div id="my-toc-content"></div> quelque part dans le body, il récupère les niveaux de titres du document grâce au script class extender ci-dessous-->
<script src="createToc.js"></script>
<script>
class handlers extends Paged.Handler {
constructor(chunker, polisher, caller) {
super(chunker, polisher, caller);
}
//register handler beforeParsed() and call createToc script
beforeParsed(content) {
createToc({
content: content,
tocElement: "#my-toc-content",
titleElements: ["h1", "h2", "h3"],//les niveaux de titres sont à personnaliser. max 3 niveaux de titres autorisés dans le sommaire
});
}
}
Paged.registerHandlers(handlers);
</script>Le script secondaire permet de personnalier les niveaux de titres qui seront récupérés, apposer un id pour personnaliser en CSS le sommaire.
Il est également proposé un style pour le sommaire à placer dans un fichier CSS dédié :
@media print {
@page toc {
}
#table-of-content {
page: toc;
break-before: right;
}
#list-toc-generated {
list-style: none;
padding: 0;
}
#list-toc-generated .toc-element a::after {
content: " p. " target-counter(attr(href), page);
float: right;
}
#list-toc-generated .toc-element-level-1 {
margin-top: 25px;
font-weight: bold;
}
#list-toc-generated .toc-element-level-2 {
margin-left: 25px;
}
/* counters */
#list-toc-generated {
counter-reset: counterTocLevel1;
}
#list-toc-generated .toc-element-level-1 {
counter-increment: counterTocLevel1;
counter-reset: counterTocLevel2;
}
#list-toc-generated .toc-element-level-1::before {
content: counter(counterTocLevel1) ". ";
padding-right: 5px;
}
#list-toc-generated .toc-element-level-2 {
counter-increment: counterTocLevel2;
}
#list-toc-generated .toc-element-level-2::before {
vertical-align: top;
content: counter(counterTocLevel1) ". " counter(counterTocLevel2) ". ";
padding-right: 5px;
}
/* hack for leaders */
#list-toc-generated {
overflow-x: hidden;
}
#list-toc-generated a {
color: black !important;
}
#list-toc-generated .toc-element::after {
content: ".................................................................................................................................................";
float: left;
width: 0;
padding-left: 5px;
letter-spacing: 2px;
}
#list-toc-generated .toc-element {
display: flex;
}
#list-toc-generated .toc-element a::after {
position: absolute;
right: 0;
background-color: white;
padding-left: 6px;
}
#list-toc-generated .toc-element a {
right: 0;
}
}Comment faire commencer automatiquement certains titres sur la page d’après ?
/* force the level 1 titles to always start on a new page */
h1 {
break-before: page;
}Comment imprimer notre document ?
Pour imprimer notre document, il suffit d’entrer CTRL+P dans le navigateur pour exporter au format PDF, envoyer vers une imprimante…
Pourquoi avoir choisi tufte.css
La feuille de style CSS Tufte reprend les idées démontrées par les livres et les documents d’Edward Tufte. Ce dernier a théorisé la présentation d’information au format texte pour qu’elle soit le plus compréhensible possible. Le style de Tufte est connu pour la mise en forme des graphiques et tableaux, le choix des polices d’écriture adaptées en fonction du type de contenus et l’utilisation de notes de marge.
L’objectif de « Tufte CSS » n’est pas de dire que « les sites Web devraient ressembler à cette interprétation des livres de Tufte », mais plutôt « voici quelques techniques développées par Tufte que nous avons trouvé utiles dans l’impression; peut-être que vous pouvez trouver un moyen de les rendre utiles sur le Web ». Tufte CSS est simplement un croquis d’une manière de mettre en œuvre cet ensemble d’idées. Ce devrait être un point de départ, pas un objectif de design, car tout projet doit présenter ses informations selon les meilleures conditions.
DUCAMP Christophe, Jeff. Article CSS Tufte. 2017
Pour une description plus poussée du style Tufte et de ses usages voir le billet de blog consacré d’Arthur Perret.